Qu’est-ce qu’Apache Kafka ?

Apache Kafka est une plateforme de streaming d’événements distribuée open-source développée par la Apache Software Foundation. Elle est conçue pour gérer des flux de données en temps réel avec un haut débit et une faible latence. Kafka est implémenté en Scala et Java et est principalement utilisé dans les solutions d’analyse de big data et en temps réel, agissant comme un système de messagerie, un système de stockage ou une plateforme de traitement de flux.
Apache Kafka offre la possibilité de gérer des flux d’enregistrements ou d’événements, fonctionnant de manière tolérante aux pannes et offrant une durabilité et une redondance intégrées. Il est connu pour sa capacité à traiter de grandes quantités de données rapidement et de manière fiable, et il peut publier et s’abonner à des flux d’enregistrements, à l’instar d’une file d’attente de messages ou d’un système de messagerie d’entreprise.
Comment fonctionne Apache Kafka ?
Apache Kafka fonctionne comme un système distribué, c’est-à-dire qu’il s’exécute sur un cluster d’ordinateurs. Le cœur de Kafka est constitué des Brokers, des Topics, des Producers et des Consumers. Les Producers écrivent des données sur des Topics, qui sont des journaux d’enregistrements stockés dans Kafka. Les Consumers lisent ces Topics.
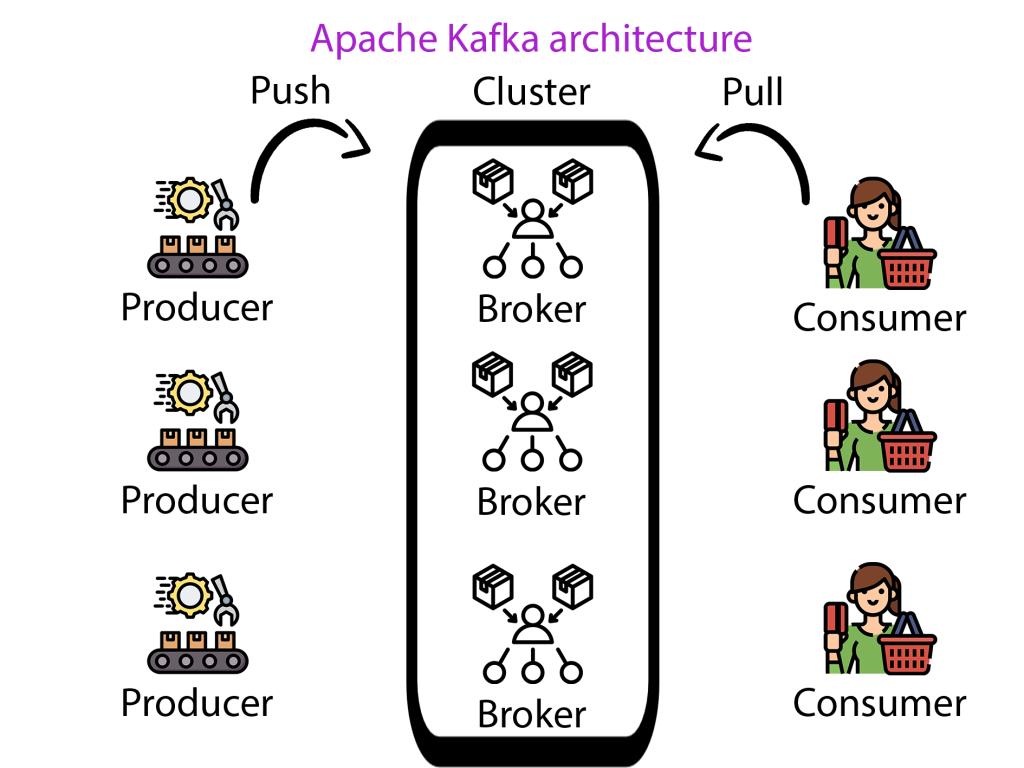
Brokers : Un cluster Kafka se compose généralement de plusieurs Brokers pour maintenir l’équilibre de la charge. Un Broker est un nœud dans le cluster Kafka et gère le stockage des données dans le cluster.
Topics : Lorsqu’un Producer envoie des données à Kafka, elles sont classées en catégories spécifiques, appelées Topics. Un Topic est essentiellement un flux de données particulier.
Producers : Les Producers sont la source des données dans Kafka. Ils envoient des enregistrements aux Brokers, qui à leur tour écrivent les données sur un Topic spécifique.
Consumers : Les Consumers lisent les données des Brokers. Ils s’abonnent à un ou plusieurs Topics et consomment les données produites pour les Topics.
La communication entre les Producers et les Consumers se fait via un protocole TCP performant et indépendant du langage. Les enregistrements sont stockés de manière durable pendant une durée configurable, permettant à plusieurs Consumers de lire les données.
Quels sont les avantages de Kafka ?
Il y a plusieurs avantages à utiliser Apache Kafka :
Haut débit : Kafka prend en charge des millions de messages par seconde, offrant un haut débit pour la publication et l’abonnement aux messages. Cette caractéristique le rend utile pour les applications de big data.
Tolérance aux pannes : Kafka est conçu pour être résilient. Il réplique les données et peut se remettre des défauts et des défaillances, garantissant qu’aucune donnée n’est perdue.
Durabilité : Kafka utilise un journal de commit distribué, garantissant que les données sont stockées jusqu’à ce qu’elles soient consommées, ce qui résulte en une excellente durabilité.

Scalabilité : Les nœuds Kafka peuvent être mis à l’échelle horizontalement sans temps d’arrêt pour gérer plus de trafic. Les Producers et les Consumers sont entièrement découplés, permettant au système de se mettre à l’échelle de manière dynamique.
Traitement en temps réel : Kafka prend en charge le traitement des données en temps réel, ce qui est crucial dans les solutions de big data et de fast data d’aujourd’hui.

Exemple concret d’utilisation d’Apache Kafka
LinkedIn, le réseau social professionnel, est un utilisateur bien connu d’Apache Kafka. Ils ont conçu Kafka pour gérer l’énorme volume de données provenant de leur site web et d’autres applications connectées. Dans leur infrastructure, Kafka traite plus d’un trillion de messages par jour.
![]()
Sur LinkedIn, différents Producers envoient des événements aux Brokers Kafka. Ces événements peuvent être déclenchés par diverses actions utilisateur, comme lorsqu’un utilisateur met à jour son profil, fait une nouvelle connexion, publie un post, ou même lorsque l’utilisateur se déplace simplement sur le site. Ces événements sont catégorisés sous différents Topics.
Par exemple, une mise à jour de profil pourrait être un Topic, et chaque fois qu’un utilisateur modifie son profil, un événement est envoyé à ce Topic. De même, les nouveaux posts pourraient être un autre Topic. Chaque Topic est alors répliqué sur plusieurs Brokers pour assurer la durabilité et la tolérance aux pannes.
Les Consumers de ces données sont généralement d’autres services au sein de LinkedIn. Par exemple, le système de recommandation est un service qui s’abonne à plusieurs Topics pour fournir des recommandations personnalisées aux utilisateurs. Il s’abonne au Topic de mise à jour de profil pour mettre à jour ses recommandations en fonction des dernières informations de l’utilisateur.
Un autre service pourrait être le système de suggestion d’emploi, qui s’abonne au Topic des mouvements de carrière des utilisateurs pour recommander les offres d’emploi les plus pertinentes. Lorsqu’un utilisateur met à jour son poste de travail sur son profil, un événement est envoyé au Topic correspondant. Le système de suggestion d’emploi consomme cet événement et met à jour ses recommandations en conséquence.
La séparation des préoccupations est également gérée par Kafka au sein de LinkedIn. Par exemple, le service de suggestion d’emploi n’a pas besoin de connaître les détails de la façon dont les données de profil sont produites. Il est uniquement concerné par la consommation des événements qui lui sont pertinents. De même, le service de profil n’a pas besoin de savoir qui consomme ses données. Cela isole les différents services les uns des autres, permettant à chaque service de se concentrer uniquement sur sa propre logique métier.
En conclusion, LinkedIn a conçu une architecture qui utilise Apache Kafka pour collecter et distribuer de grandes quantités de données en temps réel de manière fiable. Cela permet à LinkedIn de proposer des services personnalisés et interactifs à ses utilisateurs, tout en assurant l’isolation et l’indépendance de ses services.