L'”Intelligence Artificielle” (IA), est un domaine qui a connu une très grande évolution au cours des dernières années. Même si ce terme a pour la première fois été utilisé dans les années 1950, il ne s’est démocratisé que à partir des années 2000. Le terme IA se réfère à l’ensemble des méthodes et algorithmes capables de simuler l’intelligence ou le comportement d’êtres humains ou d’autres êtres vivants.
Dans cet article, nous allons nous intéresser à une branche spécifique de l’IA : le “Deep Learning”. Celui-ci est une sous-catégorie du “Machine Learning” qui désigne l’ensemble des techniques qui permettent à un ordinateur d’apprendre à partir d’un ensemble de données, sans nécessiter de règles complexes préétablies.
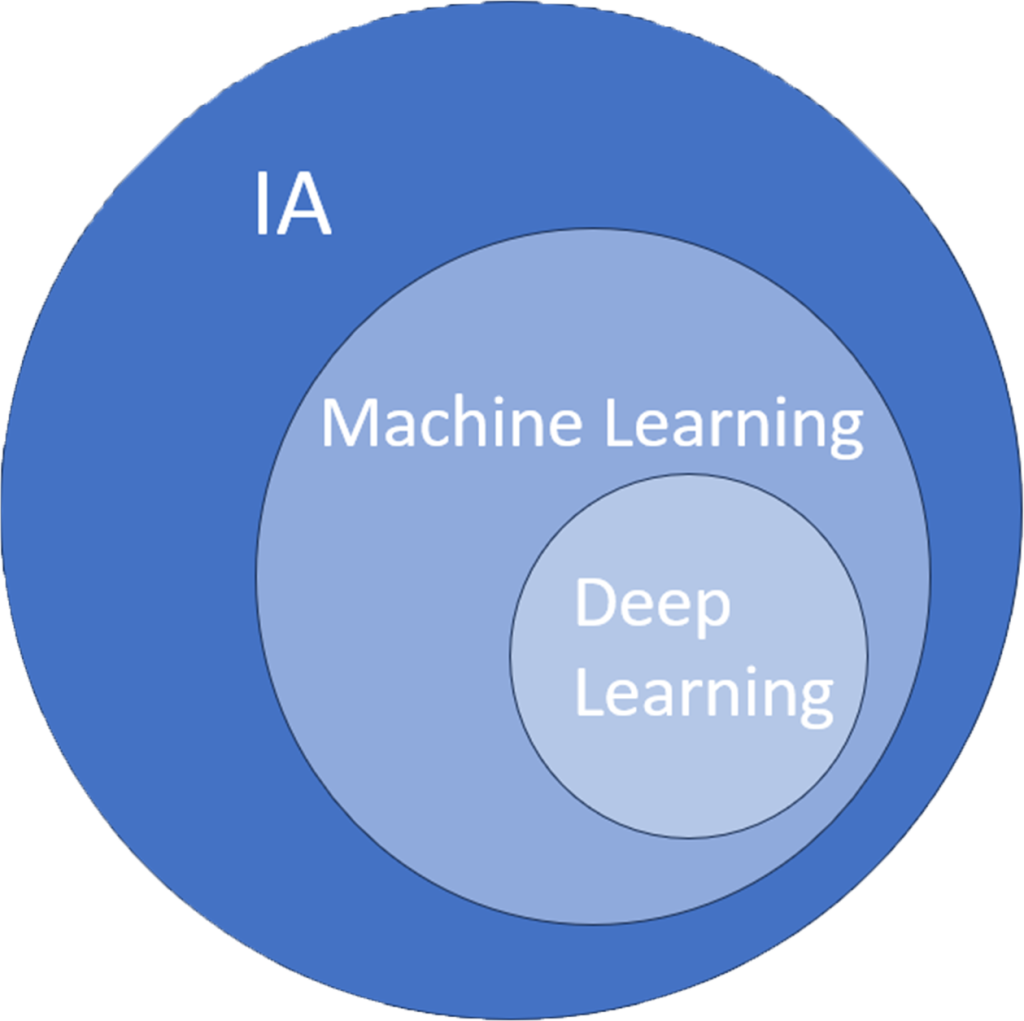
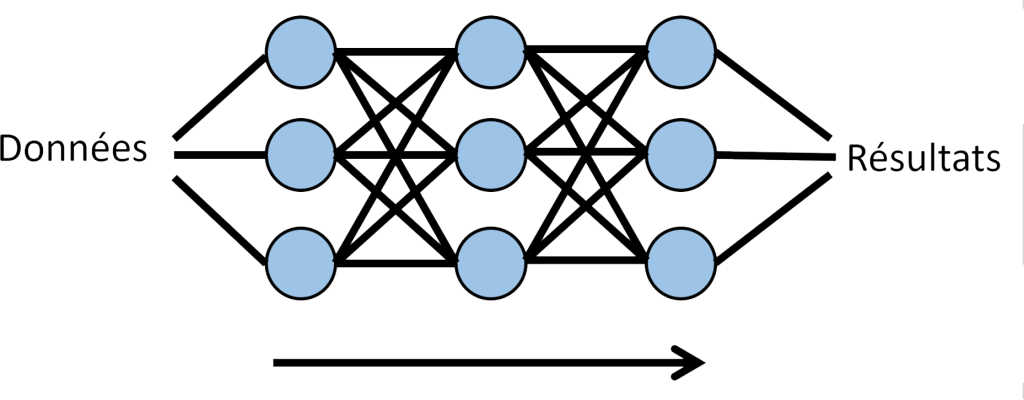
À l’instar du Machine Learning, le Deep Learning se sert de vastes ensembles de données. Cependant, sa spécificité réside dans sa structure qui s’inspire du cerveau humain, notamment des neurones. Les algorithmes de Deep Learning sont constitués de couches de “neurones artificiels” qui traitent et transmettent des informations de manière similaire aux réseaux neuronaux biologiques. Chaque couche apprend à extraire des caractéristiques différentes des données, permettant ainsi au modèle de faire des prédictions et des décisions complexes basées sur les données d’entrée. Le terme “deep” (profond) fait référence au nombre de couches dans ces réseaux : plus le nombre de couches est élevé, plus le modèle est dit profond.
Les applications du Deep Learning sont multiples et diverses, allant de la reconnaissance vocale, au diagnostic médical, et jusqu’aux véhicules autonomes. Les modèles de langage avancés, comme ChatGPT, sont d’autres exemples de l’utilisation quotidienne du Deep Learning. Ils représentent l’une des dernières avancées majeures dans le domaine. Apparus en 2018, ces modèles sont aujourd’hui implémentés dans des outils que nous sommes amenés à utiliser au quotidien : Google l’implémente de telle sorte à aider leurs utilisateurs à répondre à leurs emails, et Bing l’utilise comme un moteur de recherche innovant.
En assistant à cet essor et à l’efficacité des modèles de Deep Learning sur les tâches auxquelles ils sont entrainés, Il peut sembler compliqué d’en créer un soit-même. Cependant, il existe de nombreux outils, mis à disposition gratuitement, qui permettent de facilement mettre en place de tels modèles. Ainsi, nous allons voir ensemble un exemple concret. Pour ce faire, nous allons utiliser Google Colab ainsi que Python et TensorFlow.
Les outils pour le développement d’une IA
Développer un modèle de Deep Learning ne demande pas de grandes ressources. L’entrainer est une autre paire de manche. Cela demande non seulement un grand nombre de données de qualité, mais aussi une puissance de calcul conséquente. C’est pourquoi nous allons utiliser des outils qui mettent à disposition ces éléments cruciaux.
Tout d’abord, nous allons utiliser Google Colab, un environnement de développement Python basé sur le cloud qui offre de nombreux avantages. Il permet non seulement d’exécuter du code directement dans un navigateur, sans avoir à installer Python et toutes bibliothèques nécessaires sur son ordinateur, mais aussi et surtout, il fournit un accès gratuit à des GPU, nous permettant de disposer d’une puissance de calcul adaptée pour entrainer des modèles de Deep Learning.

L’environnement de développement se présente sous la forme d’un notebook Jupyter. Il s’agit d’un type de fichier qui se compose de blocs de code individuels, pouvant être exécutés indépendamment tout en conservant les variables déclarées en mémoire. Le langage de programmation utilisé dans ces fichiers est Python. Ce langage, grâce à sa syntaxe claire et à son large éventail de bibliothèques dédiées à l’IA, est devenu le langage de prédilection dans le domaine de l’intelligence artificielle.
Parmi la panoplie de bibliothèques disponibles pour le développement en intelligence artificielle, Tensorflow se distingue nettement comme l’une des plus prisées. Cette bibliothèque open-source, mise au point et maintenue par Google, offre un écosystème complet pour concevoir, développer et déployer des applications d’apprentissage automatique et de Deep Learning.

Tensorflow propose une interface de bas niveau permettant un contrôle granulaire sur les modèles de Machine Learning, ce qui est particulièrement utile pour la recherche et le développement de nouvelles méthodes d’apprentissage. Elle fournit également des outils robustes pour le déploiement de modèles à grande échelle, sur une variété de plateformes matérielles, allant des smartphones aux serveurs équipés de plusieurs cartes graphiques.
Cependant, pour nous faciliter un peu la tâche sans compromettre la puissance et la flexibilité que nous offre la bibliothèque, nous allons utiliser Keras, une bibliothèque de haut niveau intégrée à Tensorflow. Keras rend l’interaction avec Tensorflow plus intuitive, en encapsulant les détails techniques derrière une interface utilisateur simplifiée.
Keras permet va nous permettre de construire des réseaux de neurones en assemblant des couches, de manière semblable à l’assemblage de briques Lego. Cette abstraction simplifiée du processus de développement rend l’apprentissage du Deep Learning plus accessible et permet de gagner un temps précieux lors de la mise en œuvre de modèles couramment utilisés. De plus, Keras offre une grande flexibilité pour définir des modèles personnalisés, ce qui est crucial pour répondre à des problématiques d’apprentissage automatique plus spécifiques.
Création d’un premier modèle pour la reconnaissance d’images
Pour créer votre premier fichier et lancer Google Colab, connectez-vous à votre compte Google et accédez à Google Drive. Créez un nouveau fichier avec un clic droit en sélectionnant bien google Colab comme type de fichier. Cela ouvrira automatiquement Google Colab dans un nouvel onglet.
Pour accéder à la puissance de calcul des GPU, rendez-vous dans le menu « Exécution », cliquez sur « Modifier le type d’exécution » et sélectionnez dans « GPU » dans « Accélérateur matériel ».
Le modèle que nous allons mettre en place est un modèle de reconnaissance d’images relativement simple, qui se basera sur le jeu de données MNIST. Ce jeu de données contient 70 000 images de chiffres écrit à la main. Notre modèle prendra ainsi en entrée ces images de chiffres manuscrits, et nous donnera le chiffre qu’il reconnait sur l’image.
La première étape est d’importer les librairies et objets nécessaires, comme les types de couche que nous allons utiliser. Dans le premier bloc de code, écrivez les lignes suivantes :
import tensorflow as tf
import tensorflow.keras as tk
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.models import SequentialEnsuite, nous allons charger les données du jeu de données MNSIT avec la ligne suivante :
(x_train, y_train), (x_test, y_test) = mnist.load_data()Cela nous permet de le séparer en deux parties, un premier ensemble « train » qui va nous permettre d’entraîner notre modèle, et un deuxième ensemble « test » qui nous permettra d’évaluer notre modèle sur des données qui lui sont inconnues. Cependant, nous ne pouvons pas donner les données telles quelles au modèle. Les lignes suivantes permettent de restructurer nos données, de les normaliser et de les mettre dans un format plus adapté comme entrée du modèle :
num_examples = x_train.shape[0]
img_size = x_train.shape[1]
x_train = x_train.reshape(num_examples, img_size, img_size, 1)/255
x_test = x_test.reshape(x_test.shape[0], img_size, img_size, 1)/255
num_classes = 10
y_train = tk.utils.to_categorical(y_train, num_classes)
y_test = tk.utils.to_categorical(y_test, num_classes)L’étape suivante consiste à construire notre modèle. La construction d’un modèle peut être vu comme un empilement de blocs, où chaque bloc représente une couche de neurones. Comme nos données sont constituées d’images, nous devons transformer ces images bidimensionnelles en un format que notre modèle peut comprendre. C’est là qu’intervient la première couche, la couche « Flatten ». Elle prend notre image bidimensionnelle et l’aplatit en un tableau unidimensionnel. Ensuite, nous avons deux couches « Dense ». Ce sont des couches entièrement connectées, ce qui signifie que chaque neurone de chaque couche est connecté à chaque neurone de la couche suivante. Cette interconnexion permet au modèle d’apprendre des représentations plus complexes des données.
model = Sequential()
model.add(Flatten(input_shape=(28, 28, 1)))
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))Une fois le modèle construit, il faut le compiler et l’entrainer :
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)Une fois l’entrainement terminé, nous pouvons évaluer ses performances sur les données « test » :
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)Voilà, nous avons construit ensemble un premier modèle de Deep Learning, certes très simple, mais qui permet d’en faire une première application. Cependant, le domaine du deep learning est vaste et regorge de possibilités. Il existe de nombreux autres types de modèles, tels que les réseaux de neurones convolutifs (CNN), qui sont des modèles spécialement construit pour la reconnaissance d’image, ou les réseaux antagonistes génératifs (GAN) qui permettent, à partir d’un ensemble d’images, de créer de nouvelles images similaires.